
A pocas horas del inicio de la conferencia Google I/O, una filtración masiva ha sacado a la luz lo que podría ser Veo 4, o posiblemente Gemini Omni, un nuevo sistema de inteligencia artificial para generación de video. Las revelaciones sugieren un salto evolutivo que va más allá de producir clips cortos: la máquina estaría aprendiendo a narrar con lógica de director.
En los días previos, un video hiperrealista de un profesor escribiendo fórmulas en una pizarra se volvió viral, sirviendo como anticipo. Ahora, los indicios apuntan a que la tecnología puede construir escenas completas desde múltiples perspectivas, alternando entre planos con una fluidez que mantiene la coherencia espacial y temporal.
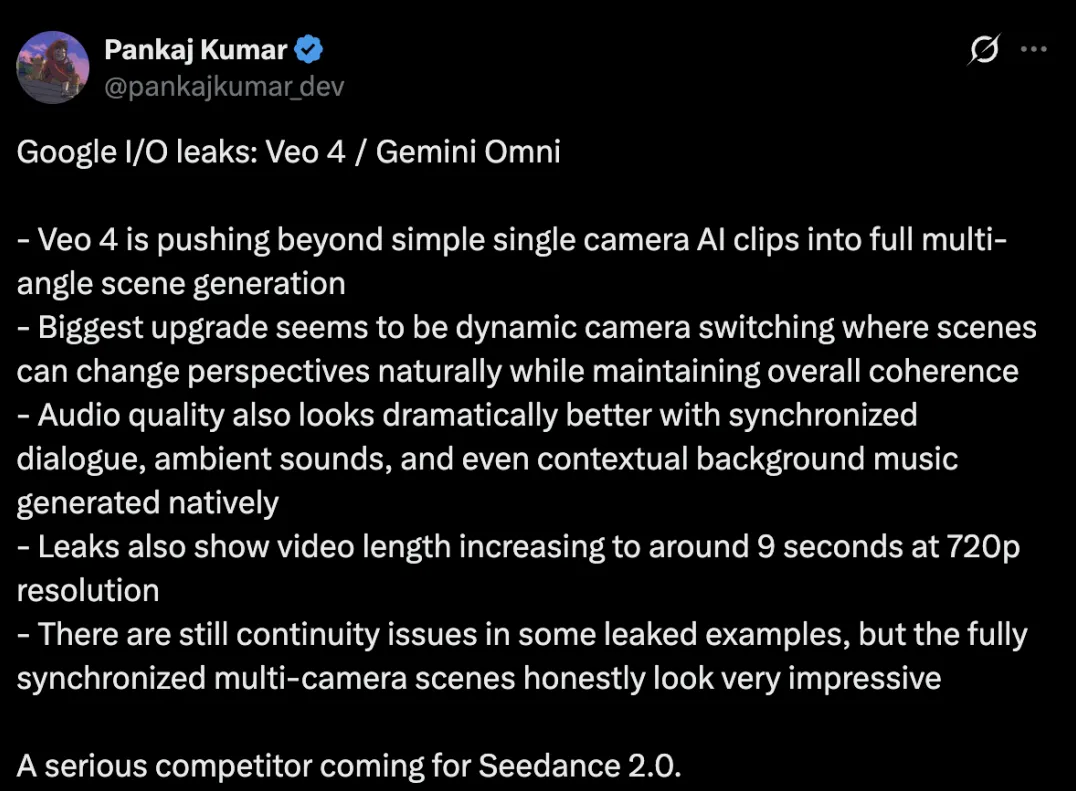
El modelo integraría de forma nativa una capa de audio sincronizado, capaz de manejar diálogos, sonidos ambientales y música contextual generada automáticamente según la situación. Los fragmentos de video alcanzarían hasta 9 segundos de duración con una resolución de 720p.

Aunque ciertos ejemplos filtrados aún muestran problemas de continuidad, la capacidad de sincronizar múltiples ángulos de cámara de forma totalmente armónica es lo que realmente ha sacudido a la comunidad. La filtración, proveniente del analista Pankaj Kumar, sugiere que Google podría generar clips de 15 segundos con relativa facilidad, pero la actual escasez de potencia de cómputo obliga a la compañía a centrarse en la eficiencia.
Habrá que esperar al evento I/O para confirmar si el anuncio oficial corresponde a Veo 4 o a Gemini Omni.

La irrupción del multicámara representa un cambio de paradigma. Hace un año, cuando Sora de OpenAI asombró al mundo, los videos generados eran esencialmente planos secuencia continuos, sin cortes reales. La inteligencia artificial no podía recrear el mismo instante desde diferentes ángulos manteniendo la consistencia de los objetos, los colores y las posiciones. La filtración de Veo 4 indica que este modelo ha interiorizado la lógica de la dirección cinematográfica, permitiendo que el sistema actúe como un narrador con sentido espacial y no como un simple pintor de fotogramas.

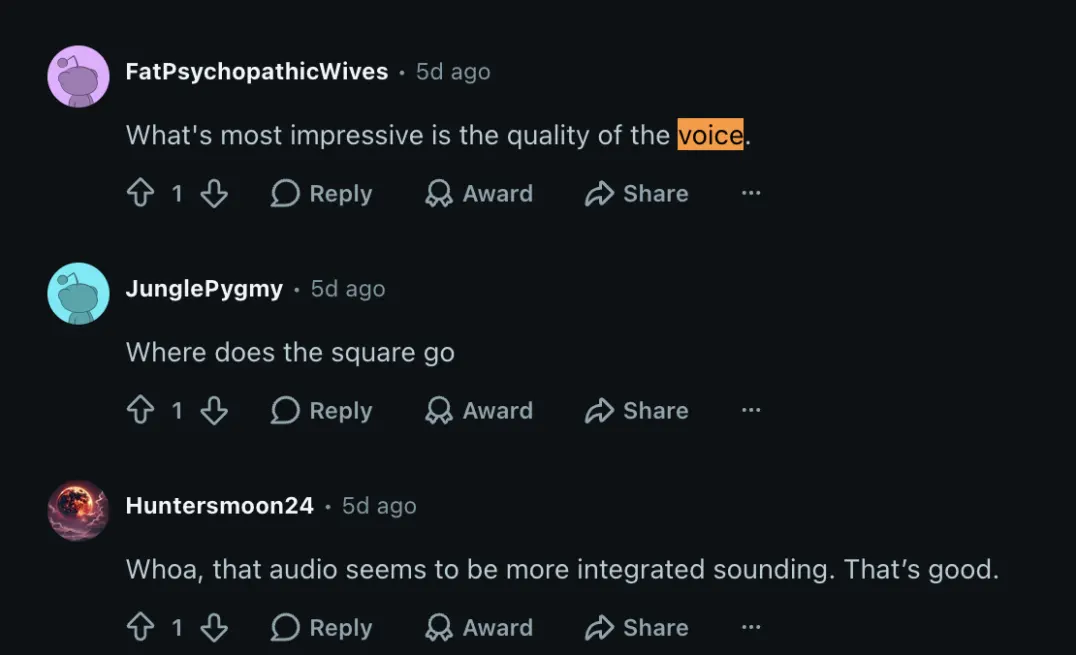
El audio completa el rompecabezas. Aunque Veo 3 ya ofrecía generación de audio nativo con pasos y conversaciones, el nuevo modelo promete una calidad sonora más realista y la adición de bandas sonoras que se adaptan al contexto de la imagen.

Los primeros usuarios en Reddit que probaron la versión anterior recibieron con entusiasmo aquel avance, pero el nuevo salto aspira a dejar atrás la sensación de artificialidad en las voces y efectos.
La revelación de Veo 4 ocurre sobre las cenizas de su predecesor simbólico. El 26 de abril, la aplicación Sora de OpenAI cesó sus operaciones, víctima de unos costos de inferencia insostenibles que la industria estimaba entre 1 y 15 millones de dólares diarios, con una base de usuarios en declive y una monetización irrisoria que apenas cubría una fracción de la factura de computación.

La cuenta oficial de Sora se despidió el 24 de marzo, y la API se cerrará por completo el 24 de septiembre.

Google, mientras tanto, no se presenta en I/O solo con video. La misma oleada de filtraciones reveló que la compañía planea lanzar múltiples modelos Gemini, incluyendo Gemini 3 Flash, la serie completa 3.1 y a Lyria 3 Pro, enfocada en audio de alta fidelidad.

El documento interno más revelador indica que el modelo Omni contará con versiones Agent especializadas para todos los productos principales, una señal de que la hoja de ruta busca integrar video, audio y marcos de acción autónoma en una sola plataforma.






