
La comunidad académica y estudiantil tiene un nuevo aliado. En las últimas horas, un desarrollador ha publicado en GitHub un conjunto de herramientas que automatiza la investigación académica utilizando inteligencia artificial. Se trata de un paquete de habilidades para Claude Code que integra todas las etapas de la producción científica, desde la revisión de literatura hasta la versión final del manuscrito.
El proyecto se llama academic-research-skills, abreviado como ARS, y se define como un conjunto integral de instrucciones y agentes autónomos. Su propuesta es simple pero ambiciosa: articular en una sola línea de comandos las cuatro fases críticas de cualquier investigación. Estas habilidades cubren la investigación profunda, la redacción, la revisión por pares y la finalización del documento.

La instalación se realiza con apenas dos comandos, lo que configura de inmediato un sistema que promete encargarse de la cadena de producción académica completa. Una solución que habría sido recibida con entusiasmo en cualquier programa de posgrado.

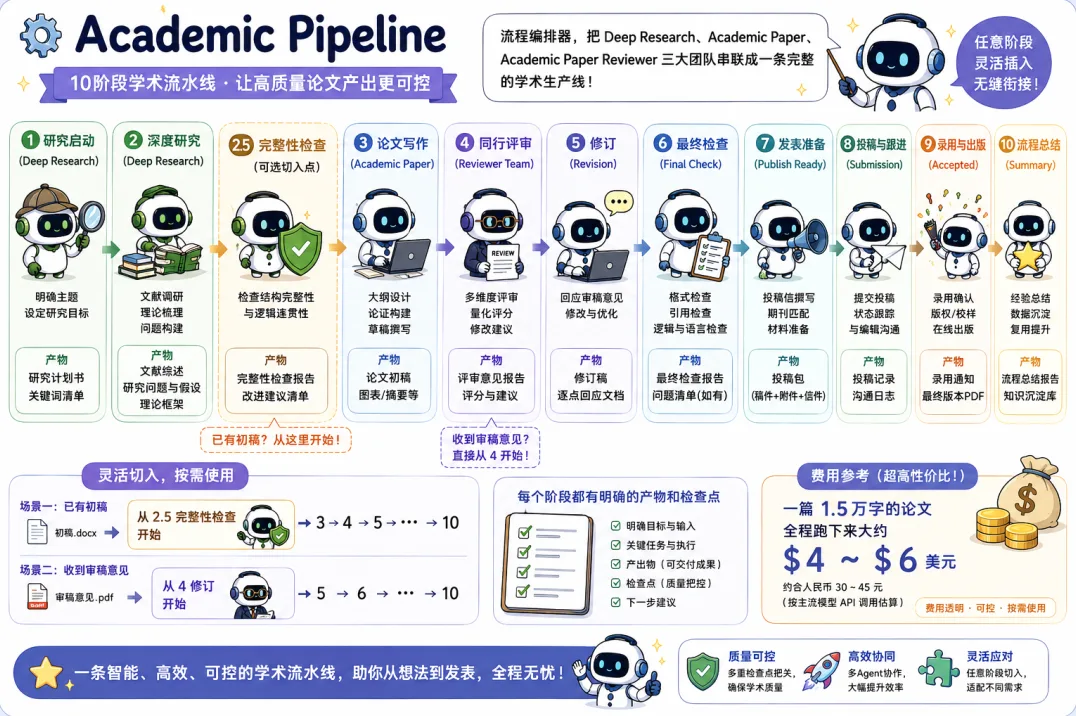
La arquitectura central de ARS se compone de cuatro habilidades especializadas que operan de forma secuencial. Juntas, forman un flujo de trabajo que va del planteamiento del tema a la entrega del artículo listo para publicar. El siguiente esquema ilustra de manera sencilla esta integración.

La primera habilidad, Deep Research, despliega un equipo de 13 agentes. Se encarga de la revisión de literatura, la formulación de preguntas de investigación y el diseño metodológico. Además, es capaz de redactar revisiones sistemáticas bajo el estándar PRISMA. Dentro de este equipo hay un agente dedicado a rastrear las fuentes bibliográficas, que verifica la autenticidad de cada cita mediante la API de Semantic Scholar. También destaca un agente que actúa como tutor socrático, guiando al investigador a través del diálogo para clarificar sus ideas, junto a un agente conocido como el abogado del diablo, cuya función es buscar fallos y evitar sesgos de pensamiento desde el inicio.
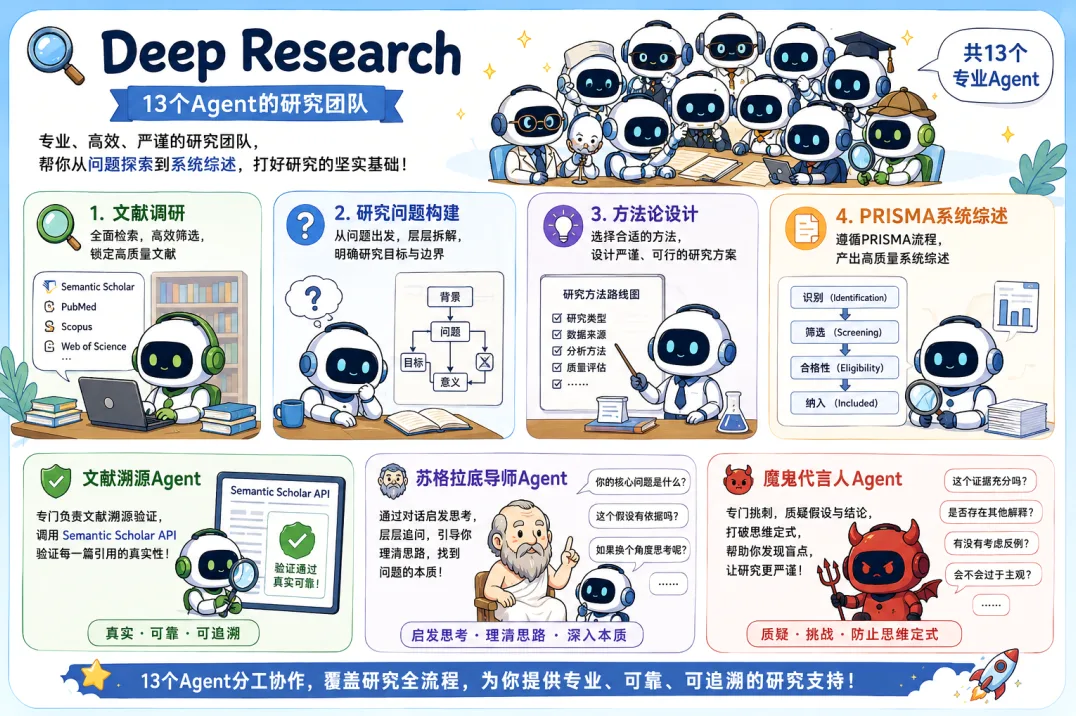
La segunda habilidad, Academic Paper, es un equipo de escritura compuesto por 12 agentes. Cubre el proceso completo, desde el diseño de esquemas y la construcción de argumentos hasta la redacción de borradores, la generación de resúmenes bilingües y la conversión de formatos de citas. Un aspecto particularmente relevante es su función de calibración de estilo. La inteligencia artificial analiza trabajos previos del autor para imitar su forma de escribir, logrando que el resultado final tenga una voz personal y no el tono genérico de la IA. El texto puede exportarse en formatos Markdown, DOCX o LaTeX, y compilarse como un PDF bajo las normas APA 7.0 o IEEE.
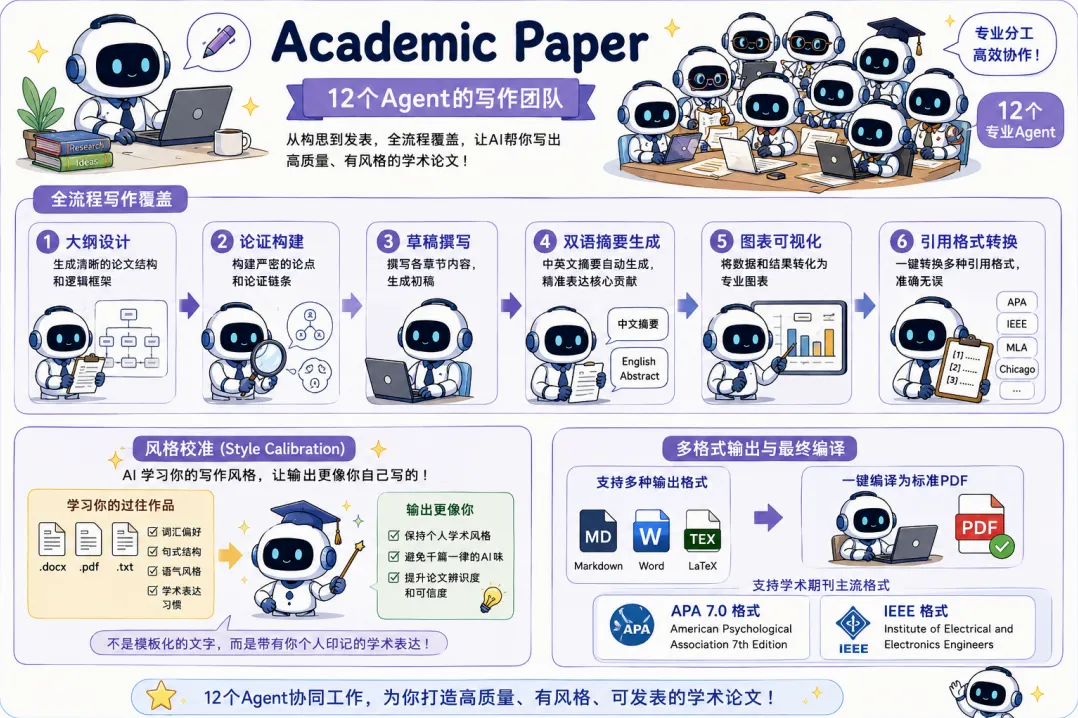
La tercera es Academic Paper Reviewer, un comité de revisión de 7 agentes. Simula el proceso de evaluación de una revista científica real. Está dirigido por un editor en jefe que coordina a tres revisores especializados y un abogado del diablo. Evalúan el artículo desde múltiples perspectivas, como la metodológica, la disciplinar y el valor interdisciplinario. Utilizan una escala cuantitativa de 0 a 100 puntos. Un artículo con más de 80 puntos es aceptado; entre 65 y 79, requiere correcciones menores; entre 50 y 64, mayores; y por debajo de 50, es rechazado. El equipo revisor produce además una hoja de ruta detallada con las modificaciones necesarias.
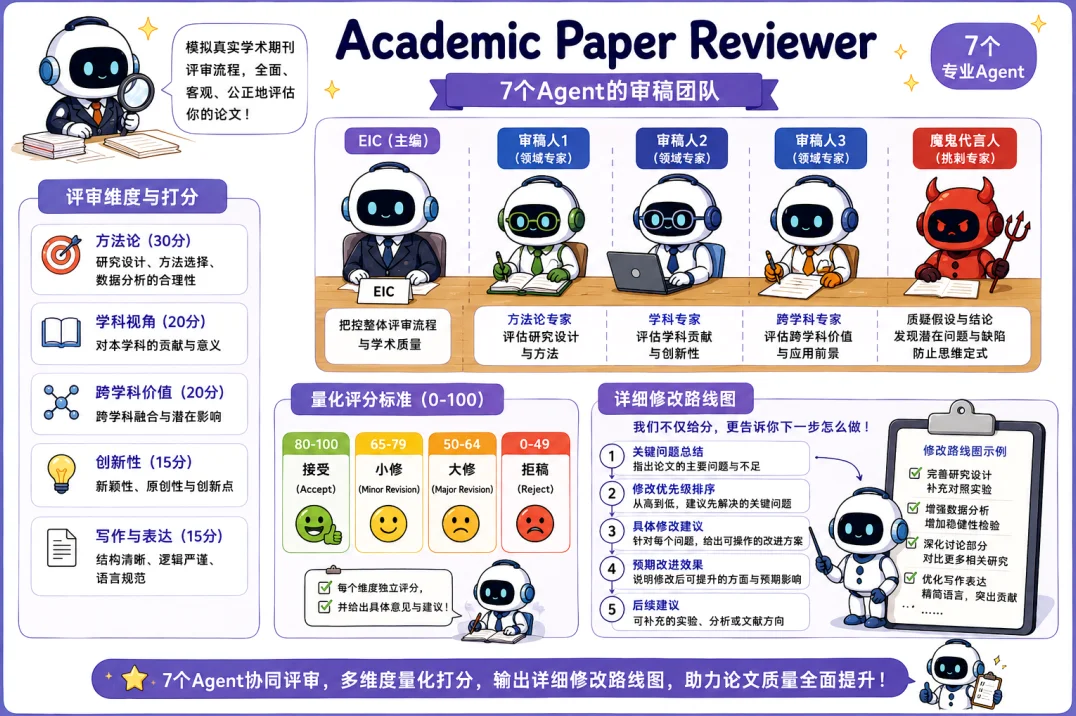
La cuarta habilidad, Academic Pipeline, funciona como el orquestador que conecta a los tres equipos anteriores en un flujo de 10 etapas. Este flujo abarca desde la investigación y la redacción, pasando por una verificación de integridad y la revisión por pares, hasta la corrección final, la preparación para publicación y un resumen del proceso. Cada etapa genera un producto específico y tiene puntos de control definidos. El sistema permite flexibilidad para comenzar en cualquier fase. Si ya se tiene un borrador, se puede iniciar en la etapa 2.5 de verificación de integridad; si se han recibido comentarios de revisores, se puede retomar directamente desde la etapa 4 de correcciones. El costo estimado es transparente: procesar un artículo de 15 mil palabras a través de todo el flujo tiene un costo de entre 4 y 6 dólares.
Más allá de su funcionalidad, el proyecto esconde elecciones de diseño notables. Aunque existen muchos proyectos similares, ARS destaca en su estrategia para prevenir fallos catastróficos de la IA en contextos académicos.
El primer punto es la verificación de citas. El mayor riesgo de la IA en este ámbito son las citas alucinadas, referencias inventadas o con errores sutiles como la confusión de autores y años. Para combatirlo, ARS incorpora en su fase de investigación un mecanismo que confirma cada referencia contra la API de Semantic Scholar. No es una simple comprobación del título, sino una coincidencia difusa mediante un algoritmo de similitud de Levenshtein, que exige un umbral superior a 0.70 para validar una fuente.
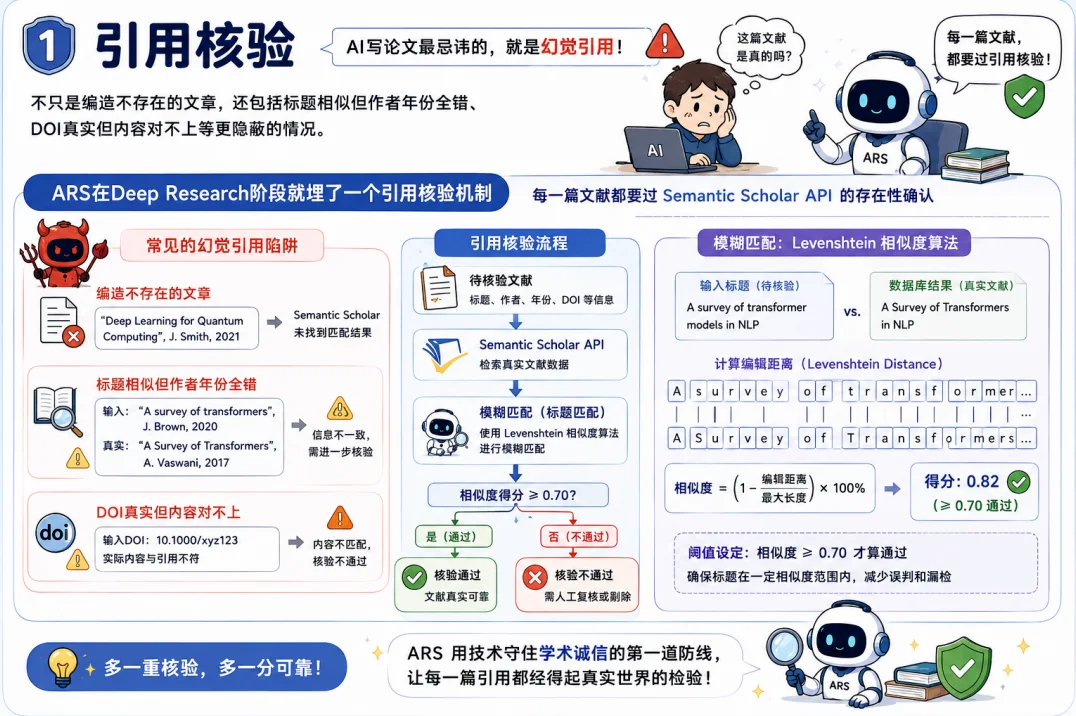
En segundo lugar, están las puertas de integridad. En las etapas 2.5 y 4.5 del flujo de trabajo, existen dos puntos de control obligatorios que ejecutan una lista de 7 modos de fallo de la IA. Esta lista se basa en un estudio sobre investigación científica autónoma con IA publicado en Nature en 2026, que documenta problemas como la invención de citas, la falsificación de datos o el falseamiento metodológico.
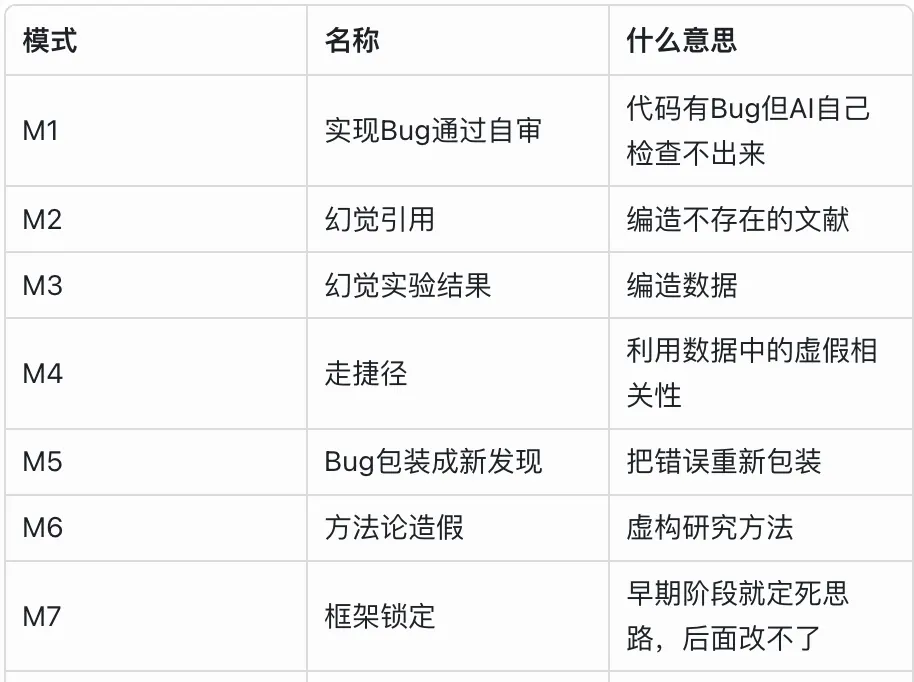
Cualquier problema marcado como SOSPECHOSO en la etapa 2.5 debe forzosamente resolverse como ACLARADO en la etapa 4.5, o bien ser desestimado de forma manual por un humano, dejando un registro de la acción. La filosofía es transformar la confianza pasiva en una exigencia de pruebas. En pruebas reales, este sistema detectó 15 citas fabricadas y 3 errores estadísticos en un solo artículo.
El tercer pilar es un protocolo contra la adulación. Muchas herramientas de IA tienden a complacer al usuario, realizando cambios que empeoran el resultado. El sistema de revisión de ARS cuenta con un mecanismo para evitarlo. El abogado del diablo presenta objeciones, pero existe un umbral de concesión. Sus refutaciones se puntúan del 1 al 5; si su puntuación es inferior a 4, el equipo de redacción tiene prohibido admitir ese cambio.

Esto significa que la IA no puede ceder solo para facilitar la colaboración. La intensidad del ataque debe mantenerse durante todas las revisiones, y si una nueva versión obtiene una puntuación inferior a la anterior en cualquier dimensión, se registra como una regresión. El principio es equivalente a la regla de no introducir nuevos errores en el código al reparar uno.
El cuarto elemento es un sistema de aislamiento de datos en tres capas. La Capa 1 contiene los datos de entrada, que se presumen no fiables, potencialmente alucinados, obsoletos o sesgados. La Capa 2 agrupa los resultados que han pasado las verificaciones de integridad. La Capa 3 incluye los estándares de puntuación, las respuestas de referencia y los datos de validación de alta calidad. Los materiales de esta tercera capa nunca pueden aparecer en el contexto de la IA de escritura. Los equipos de revisión y redacción operan en llamadas independientes y aisladas. El escritor solo recibe la retroalimentación en lenguaje natural, no ve los criterios de puntuación ni los pesos de cada categoría.
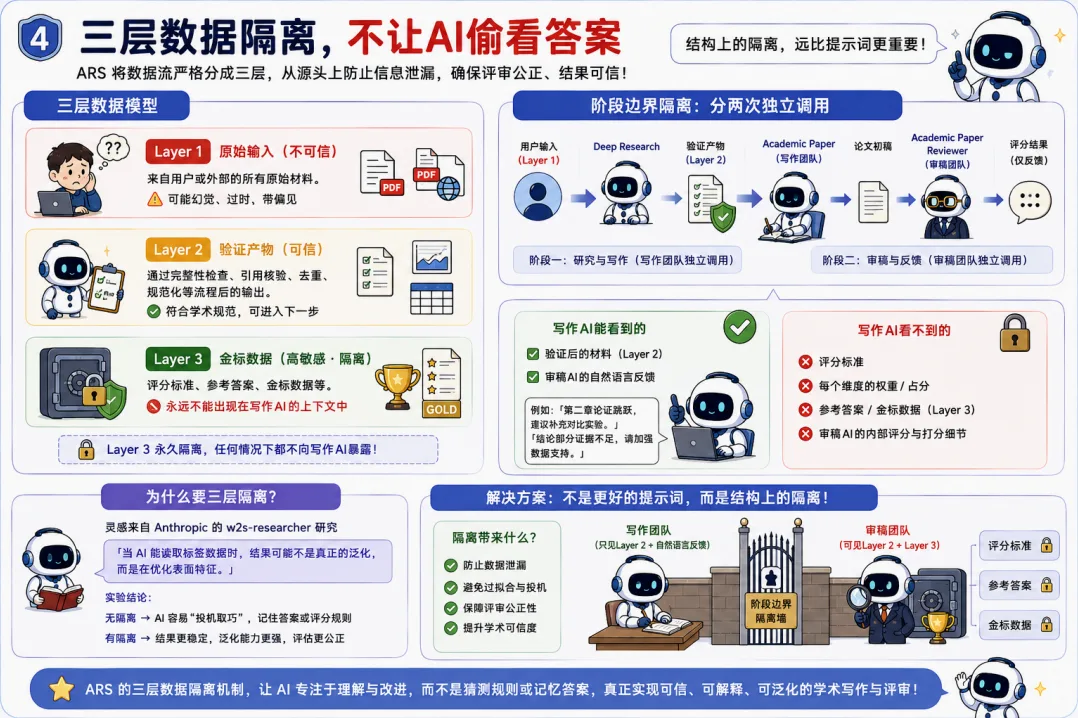
Este diseño se inspira en el modelo de aislamiento de tres capas del proyecto w2s-researcher de Anthropic. La conclusión de aquel trabajo fue que, si una IA puede leer los datos de referencia, podría estar optimizando rasgos superficiales en lugar de generalizar de verdad. La solución no es un mejor mensaje para la IA, sino una separación estructural.
Un último detalle es lo que llaman documentación honesta. El sistema genera un archivo repro_lock para cada producto que registra la configuración exacta de la ejecución. Sin embargo, el archivo incluye una declaración explícita que advierte que la salida de un modelo de lenguaje no es reproducible a nivel de bytes. Los proveedores de modelos pueden actualizar sus pesos sin cambiar el identificador de la API, y los servicios externos devuelven datos distintos cada día. Ese archivo es una documentación de la configuración, no una garantía de réplica.

El registro de cambios del proyecto, con más de trescientas confirmaciones desde su lanzamiento en febrero, refleja una evolución constante y una comprensión de los riesgos sistémicos de la IA en la academia. La clave de esta herramienta no es la facilidad para generar texto, sino la sofisticación para prevenir errores, evitar sesgos de complacencia y hacer el proceso más fiable. Tal como lo resume el archivo README, su filosofía es clara: la IA debe ser el copiloto, nunca el piloto.
Para empezar a usarlo con Claude Code, basta con ejecutar dos comandos en la terminal. El primero añade el mercado de complementos y el segundo instala las habilidades.
Para verificar que todo funciona, se puede lanzar una planificación con el comando correspondiente y describir el tema del artículo. El sistema inicia un diálogo socrático para estructurar la investigación. También es posible ejecutar una sola habilidad de forma directa, por ejemplo, pidiendo una revisión de literatura sobre un tema concreto.
La forma más simple de probarlo, sin embargo, es subir el archivo de instrucciones al repositorio de conocimiento de un proyecto en claude.ai. Esto permite usarlo con el navegador, sin necesidad de Claude Code, aunque en ese modo no se ejecutan múltiples agentes en paralelo y la funcionalidad se limita a un solo agente. Para aprovechar el flujo completo de la tubería, es imprescindible Claude Code.
En cuanto al costo, el autor recomienda usar el modelo Claude Opus 4.7 con un plan de suscripción Max. Completar las 10 etapas del flujo puede consumir más de 200 mil tokens de entrada y 100 mil tokens de salida. El costo de los planes de suscripción Max es de 100 o 200 dólares mensuales, una suma considerable a menos que se disponga de financiamiento para investigación.

El creador del proyecto es Edward Cheng-I Wu, conocido por su avatar con un gato.

Originario de Taiwán, en su perfil de GitHub mantiene otros proyectos como una habilidad de escritura para documentos oficiales taiwaneses y una herramienta de anonimización de datos locales.





