
En los últimos días, la comunidad de código abierto ha encontrado un nuevo protagonista. Se trata de OpenHuman, un asistente de escritorio impulsado por inteligencia artificial que llega desde el laboratorio tinyhumansai. El proyecto, que se autodefine como un agente de IA con subconsciente artificial, propone un cambio de paradigma: en lugar de esperar a que el usuario le enseñe, el sistema aprende de manera automática y privada apenas conecta sus cuentas.
OpenHuman se presenta como un entorno de código abierto bajo licencia GNU. Su base técnica combina el framework de escritorio Tauri con TypeScript en el frontend y Rust en el núcleo. Pero lo que realmente lo separa de los chatbots convencionales es su memoria persistente y su capacidad para integrarse con el ecosistema digital del usuario en cuestión de minutos.
Mientras la mayoría de los asistentes actuales sufren de amnesia entre sesiones, OpenHuman despliega un sistema de árbol de memoria. Cada mensaje de correo, evento del calendario, documento o fragmento de código se convierte en un bloque de Markdown de hasta 3000 tokens. Esos bloques se puntúan por calidad, se pliegan en una estructura jerárquica de resúmenes y se almacenan en una base de datos SQLite cifrada del propio equipo. El diseño bebe directamente de las ideas que Andrej Karpathy compartió sobre su flujo de trabajo con bases de conocimiento personales, materializadas ahora en un producto que automatiza todo el proceso.
La obsesión por el contexto se extiende al resto de la arquitectura. Un motor de sincronización recorre cada 20 minutos todas las conexiones activas, ya sean Gmail, GitHub, Notion, Jira, Linear, Google Calendar, Stripe o Slack. Con más de 118 integraciones OAuth de un solo clic, el asistente no necesita que nadie le cuente en qué está trabajando: simplemente lo extrae y lo convierte en conocimiento estructurado. De ese modo, cuando el usuario escribe su primera instrucción, la IA ya dispone de un perfil completo.
El tratamiento de los datos apuesta por una estrategia local-first. Toda la memoria reside en el dispositivo del usuario, cifrada y sin depender de servidores externos. Quien quiera todavía más control puede inspeccionar los archivos Markdown directamente desde Obsidian, ya que el sistema exporta los fragmentos a un repositorio compatible con la popular herramienta de gestión de conocimiento. Además, un backend opcional llamado agentmemory permite compartir la misma memoria con otros asistentes de codificación como Claude Code, Cursor o Codex.
La eficiencia de costos ha sido otra de las obsesiones del equipo. Antes de que cualquier contenido llegue a un modelo de lenguaje, el módulo TokenJuice comprime los datos: convierte HTML a Markdown limpio, acorta las URL largas y elimina caracteres no ASCII. Según los responsables, la reducción del consumo de tokens puede alcanzar el 80 por ciento. Y para que el ahorro no penalice la calidad, OpenHuman aplica un enrutamiento inteligente de modelos. Las tareas de razonamiento complejo se derivan a modelos potentes, mientras que las respuestas rápidas o el procesamiento visual se gestionan con motores más ligeros, todo bajo una única suscripción.
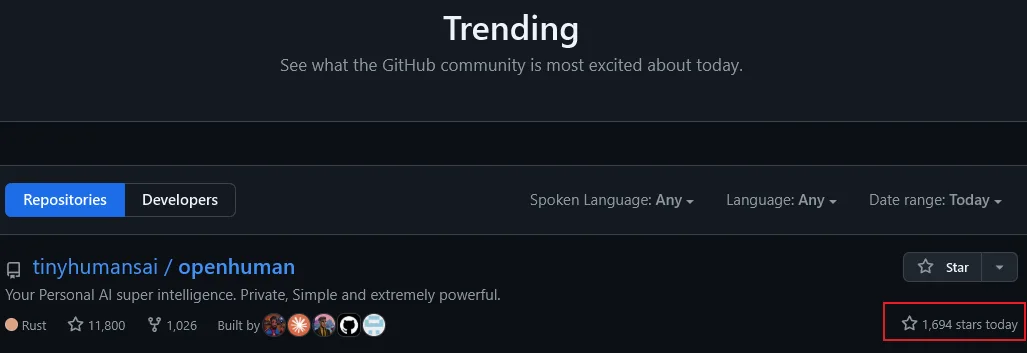
La combinación de conceptos ha disparado la popularidad del proyecto. Durante varios días ha encabezado los rankings de tendencias en GitHub con más de 1600 estrellas diarias y ha sido destacado en Product Hunt. TrendShift confirma una actividad comunitaria excepcional, con conversaciones intensas en X, Reddit e Instagram. Medios como TechTimes definen la propuesta como una inversión del guion tradicional: la IA conoce al usuario antes de recibir la primera orden.
La privacidad y la soberanía de los datos completan el argumento de adopción. Las memorias cifradas permanecen bajo control absoluto del usuario, que puede consultarlas, editarlas o eliminarlas sin pasar por la interfaz de OpenHuman. Esa transparencia total, sumada a la portabilidad de los archivos Markdown, garantiza que el conocimiento acumulado no quede atrapado en un ecosistema cerrado.
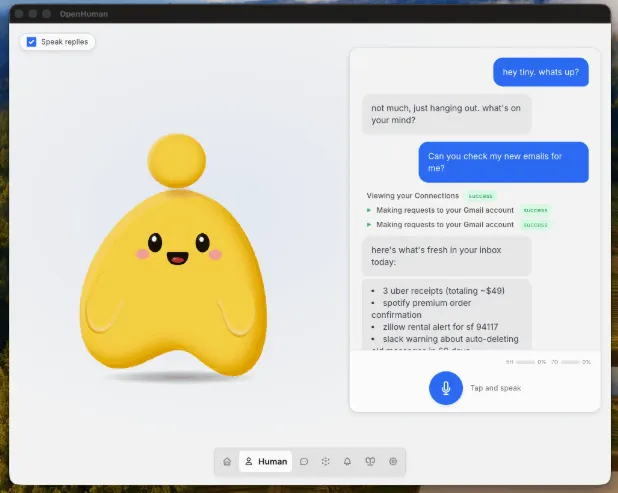
El asistente también ensaya una faceta más lúdica con un avatar de escritorio parlante. Esta mascota digital puede unirse a reuniones de Google Meet apoyándose en reconocimiento de voz, síntesis de ElevenLabs y sincronización labial. Para las cargas de trabajo sensibles, el sistema ofrece integración con Ollama, lo que permite ejecutar modelos locales sin enviar ningún dato a la nube.
Cuando se le compara con otros frameworks como LangChain o AutoGen, OpenHuman se desmarca por eliminar casi por completo la fricción de configuración. La instalación se reduce a unos pocos clics y la construcción del contexto personal se completa en la primera sincronización. Frente a los días o semanas que otros agentes necesitan para entender el ecosistema de un usuario, aquí la curva de aprendizaje se comprime a minutos.

El fenómeno OpenHuman refleja una demanda de fondo. El público técnico ya no busca una caja de chat con un modelo brillante, sino un compañero digital que comparta memoria, se anticipe a las necesidades y opere sin fronteras entre aplicaciones. El enfoque de memoria arbórea, la sincronización periódica y la filosofía local-first trazan un camino distinto al de los asistentes conversacionales. La era del asistente que solo escucha cuando le hablan empieza a dar paso a un agente que entiende, recuerda y actúa incluso antes de que el usuario termine de formular la pregunta.




